Data-augmentation for Bangla-English Code-Mixed Sentiment Analysis: Enhancing Cross Linguistic Contextual Understanding
Abstract
In today’s digital world, automated sentiment analysis from online reviews can contribute to a wide variety of decision-making processes. One example is examining typical perceptions of a product based on customer feedbacks to have a better understanding of consumer expectations, which can help enhance everything from customer service to product offerings. Online review comments, on the other hand, frequently mix different languages, use non-native scripts and do not adhere to strict grammar norms. For a low-resource language like Bangla, the lack of annotated code-mixed data makes automated sentiment analysis more challenging. To address this, we collect online reviews of different products and construct an annotated Bangla-English code mix (BE-CM) dataset (Dataset and other resources are available at https://github.com/fokhruli/CM-seti-anlysis ). On our sentiment corpus, we also compare several alternative models from the existing literature. We present a simple but effective data augmentation method that can be utilized with existing word embedding algorithms without the need for a parallel corpus to improve cross-lingual contextual understanding. Our experimental results suggest that training word embedding models (e.g., Word2vec, FastText) with our data augmentation strategy can help the model in capturing the cross-lingual relationship for code-mixed sentences, thereby improving the overall performance of existing classifiers in both supervised learning and zero-shot cross-lingual adaptability. With extensive experimentations, we found that XGBoost with Fasttext embedding trained on our proposed data augmentation method outperforms other alternative models in automated sentiment analysis on code-mixed Bangla-English dataset, with a weighted F1 score of 87%.
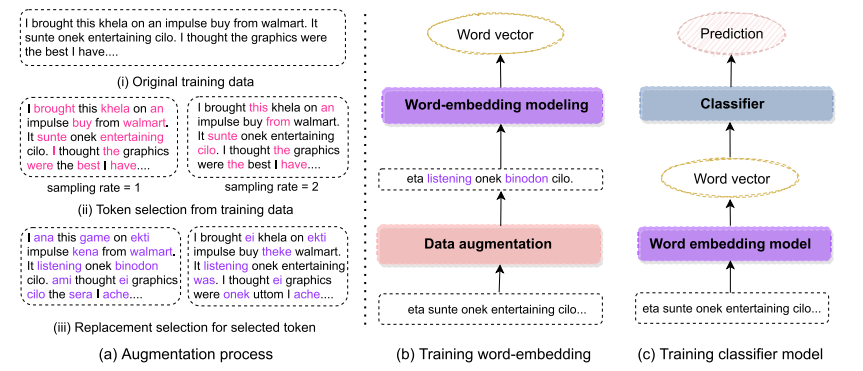
Figure: (a) Proposed data augmentation process with multiple sampling rates. For simplicity, we only showed sampling rate 1 and 2 in the above diagram. (b) Illustration of word embedding training process. We augment input data with several sampling rate. (c) Training the classifier using learned word embedding.